sonicLAB Synthesizer · Audio Processor
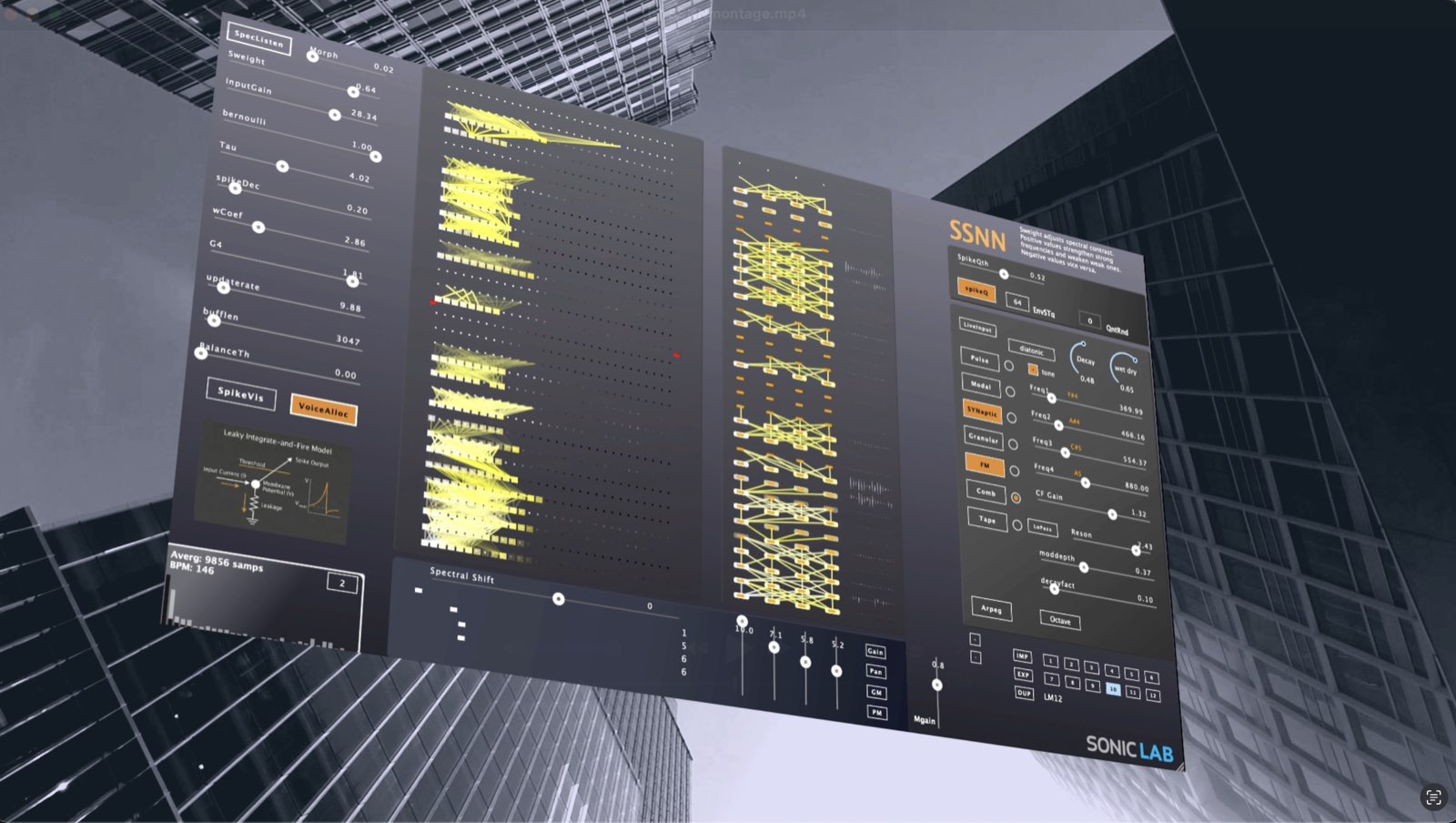
SSNN
Spiking and Sounding Neural Network
Concept by Sinan Bokesoy & Daito Manabe.
Design & programming by Sinan Bokesoy.
First release 06/2026.

Listens,
learns & resynthesizes
SSNN puts a live spiking neural network — 960 neurons across 32 layers — at the center of the synthesis path, driving eight engines in real time with each spike.
The audio you feed it creates a unique closed loop. A continuous FFT writes its spectral profile into the network's connection weights — what it learns from — while the same raw samples fill the per-layer audio buffers the synth engines sculpt — the material it's made of.
The same signal is at once the lesson and the substance. An instrument that listens, learns, and resynthesizes its own input while operating fully transparent to the user.
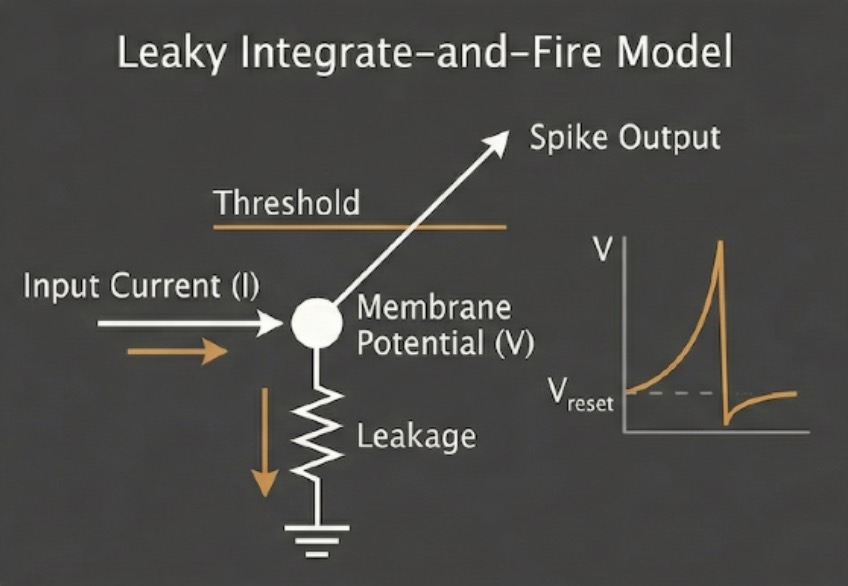
"To learn is to transform passing information into a form you can store and recall. SSNN learns by measuring the spectrum of incoming audio and storing it as connection weights — a memory that becomes the network's own activity."
Why ?
Spiking Neural Networks (SNNs) are the third generation of artificial neural networks, designed to more closely mimic how biological neurons actually communicate. While traditional artificial neural networks use continuous values, spiking networks communicate through discrete electrical impulses or "spikes" — just like neurons in your brain.
Audio is inherently temporal — music exists in time, with rhythm, melody, and harmony unfolding moment by moment. Spiking neural networks are naturally suited for temporal pattern processing, making them ideal for rhythmic pattern generation through spike timing, dynamic harmonic evolution through network states, adaptive learning from audio content, and real-time responsiveness to musical input.
sonicLAB's
unique approach
- 960 Neurons · 32 Layers A leaky integrate-and-fire spiking neural network running live alongside the audio engine. Each spike is a discrete sonic event — together they shape a continuously evolving texture.
- FFT-Driven Learning A continuous FFT analyses incoming audio and writes its spectral profile directly into the network's connection weights. The instrument is learning your input in real time.
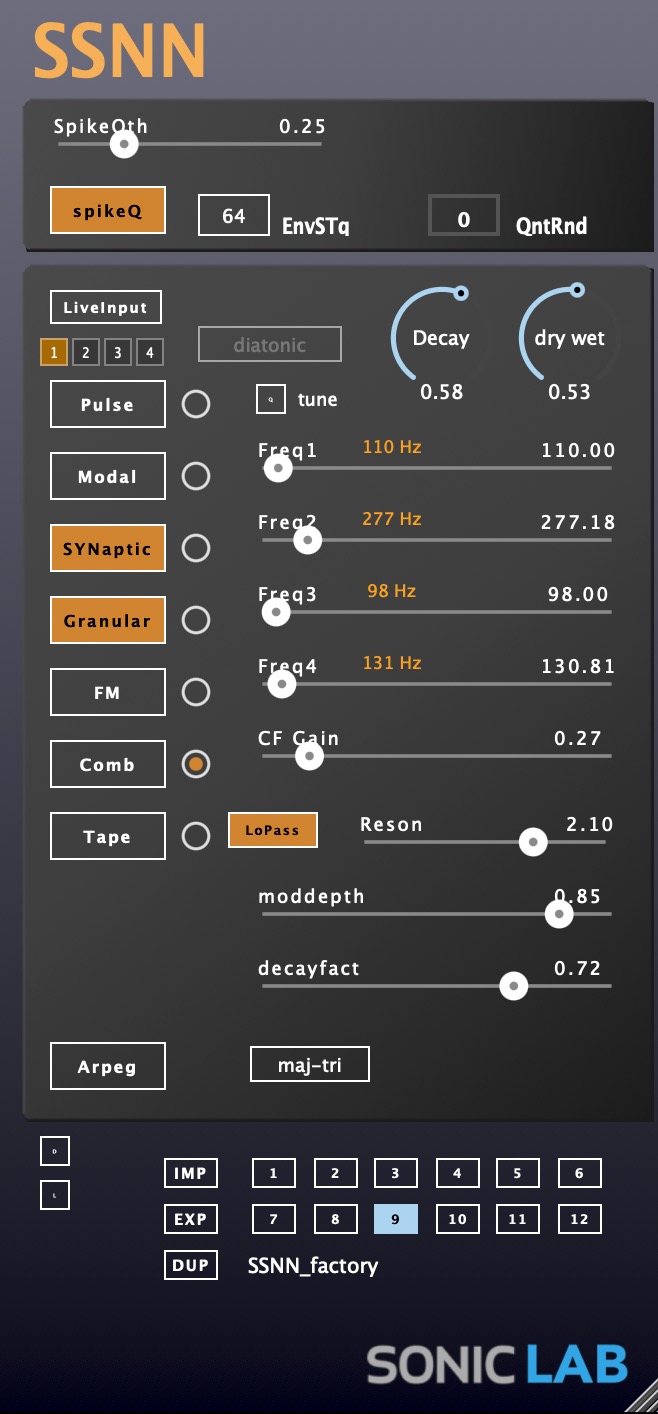
- Eight Synthesis Engines Pulse, Modal, SYNaptic, Granular, FM, Comb, Tape, Arpeg — each driven directly by the spikes of the network, sculpting the per-layer audio buffers.
- Closed Loop Resynthesis The same raw audio fills per-layer buffers the synth engines sculpt. Material and lesson are one and the same — the instrument resynthesizes its own input while remaining fully transparent to the user.
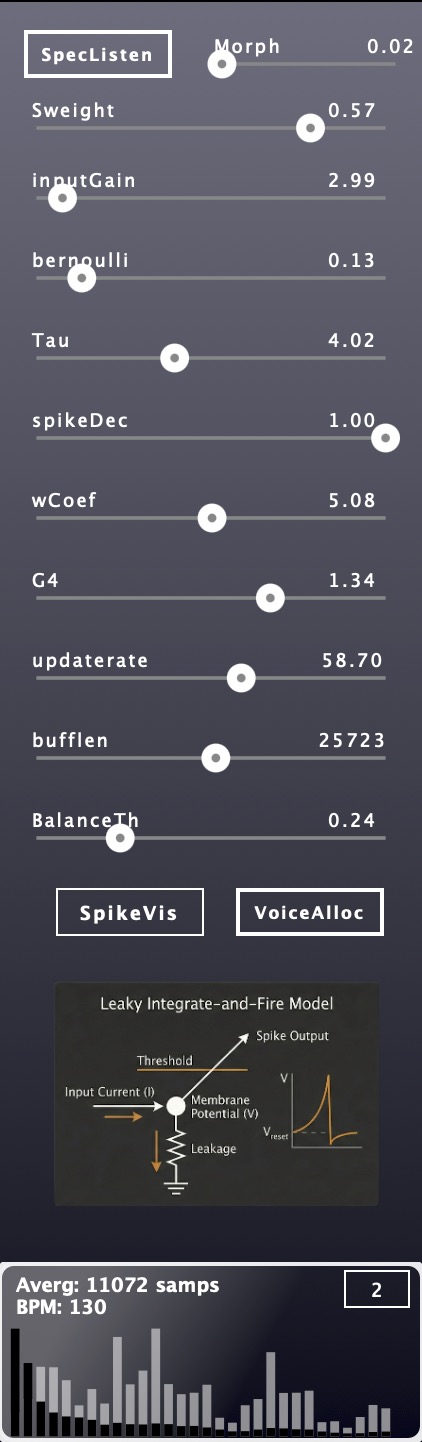
- Spectral Control Sweight adjusts spectral contrast: positive values strengthen strong frequencies and weaken weak ones, negative values vice versa. Spectral Shift, SpecListen and Morph round out the analysis stage.
SSNN learns, remembers, responds and evolves.
Full interaction
with the neural network
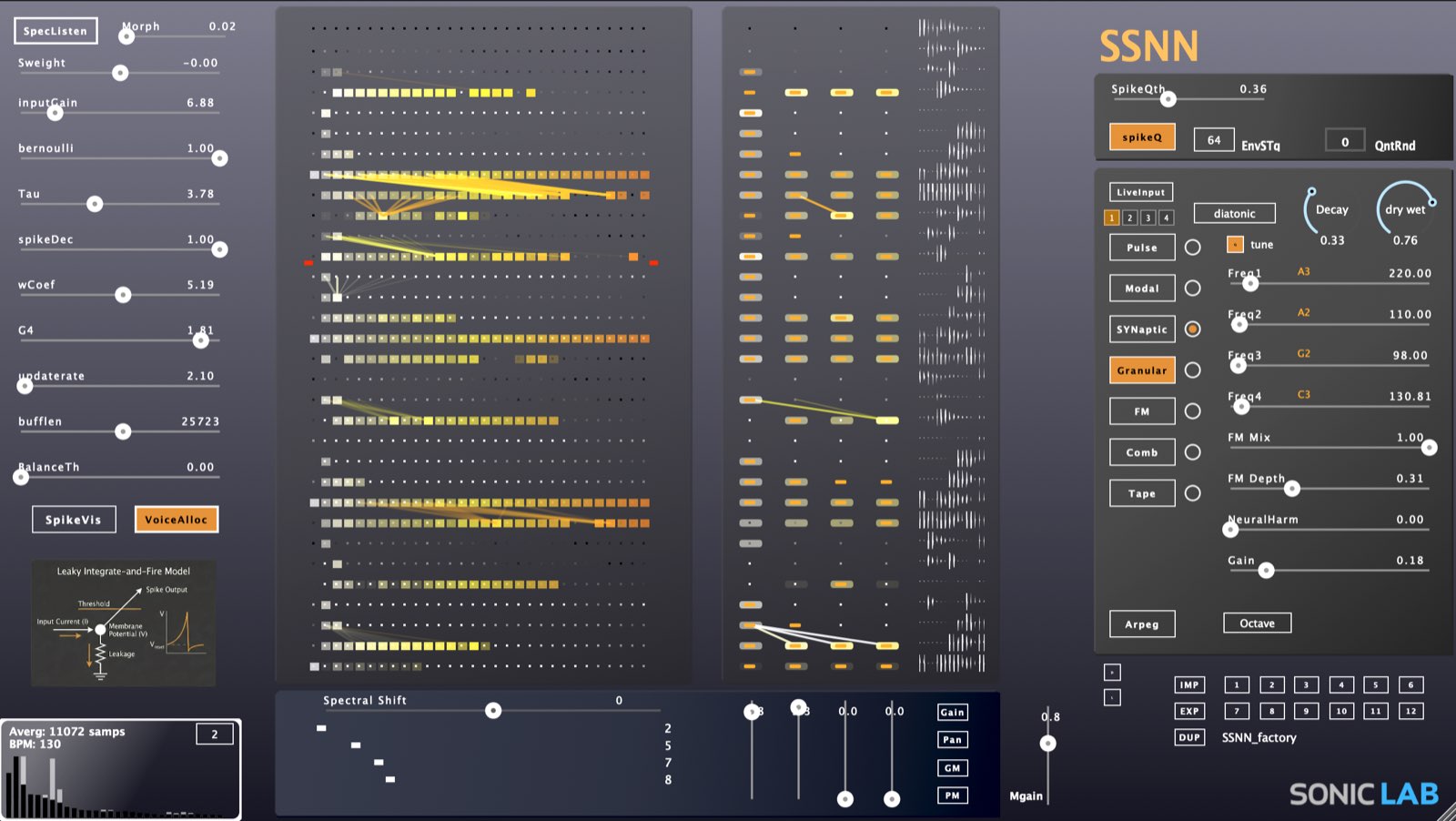
SSNN incorporates the Leaky-Integrate-and-Fire Model. And it gives you the full parameter suit where you can interact with the neural network in real time.
It offers the neural network as a true instrument which you master and discover its many sweet spots. From deterministic settings, to stochastic injections SSNN delivers a truly dynamic engine.
You can morph the learned weights of the Neural Network between a randomly distributed network in real time. You can also shift position the neural network weights.
SSNN also generates OSC messages for the spike events with high time resolution. A bundled plugin with SSNN package called NNnotes will convert these to MIDI Note events for you to drive other instruments along with SSNN.
Each of the 4 Neural Columns spike instances is routed on a different port number. And on NNnotes you can select from which port number to receive.
The synthesis engine has sound generators that operate based on data received from the neural network in real-time. These include Pulse, Modal, and SynapticFM oscillators.
The other synthesis engine components process their input audio, such as Granular, FM, CombFilter, and TapeDelay processors.
- Granular Wavetable — real-time transient detection and capture, with per-layer time offsets that read different regions of the captured material for each network layer.
- Comb Filter Resonator — physical-modeling resonance.
- Synaptic FM — FM synthesis modulated by the network's spiking output.
- Light Tape Looper — a 32-layer neural tape machine.
- Resonant Filter Bank — advanced filtering with per-layer waveshaping.
- Modal Synthesis — mimicking wood percussions.
Glitchy, dirty, full of sweet spots, accidental.
Quantization
When SpikeQ is enabled, your neural network neurons can only "fire" (trigger sounds) at specific timing intervals, like a musical metronome. Think of quantization as a set of musical "rules" that snap your neural network's wild behavior onto a musical grid, ensuring everything stays in time.
With SpikeQ off, neurons fire whenever they reach their voltage threshold, creating chaotic timing. With SpikeQ on, they wait for the next "quantized time" to fire, creating rhythmic patterns.
Arpeggiator
The SSNN arpeggiator is a 32-layer arpeggio system that transforms the neural network's layer-based architecture into musical scales and chord progressions. Each of the 32 neural network layers triggers different frequencies based on the selected arpeggio pattern, creating polyphonic harmonic structures that evolve with neural network activity.
The user can also set Scala formatted tuning scales to pitch quantize the synthesis voices.
KEY OPERATIONAL FEATURES
- — Live Spiking Neural Network with 960 neurons, 8 Synthesis engines in parallel
- — Spectral training, real time weight morphing
- — Full resizable vector UI
- — Multi core engine ( 3 workers + main thread ), oversampled output
- — Mouse pointer float on any UI element reveals a relevant info text
- — OSC Spike broadcast with high time resolution
- — Custom arpeggiator patterns and powerful quantization scheme
- — Ultra fast event management and 60hz neuron activity visual response
System
Requirements
SSNN is available in VST3 and AU formats for OSX (universal) and Windows systems.
All sonicLAB products are 64bit only.
Recommended system: Apple Silicon M1 or equivalent or better.